

The landscape of mental health research is evolving, and tools like Natural Language Processing (NLP) hold immense potential to bridge the gap between clinical trials and real-world evidence. As we strive to enhance our understanding of mental health outcomes and treatment effectiveness, a strategic implementation of NLP tools becomes pivotal.
This blog explores a high-level overview of how we developed NeuroBlu NLP - Holmusk’s NLP models specifically tailored for extracting disease-specific clinical features from unstructured clinical text. These NLP-derived clinical features are then integrated into our structured data and made available in NeuroBlu, Holmusk’s powerful data analytics software for behavioral health. The incorporation of NLP-derived features into structured data provides a more comprehensive, easily accessible estimate of patient phenotypes in the real-world, ultimately benefiting patient care.
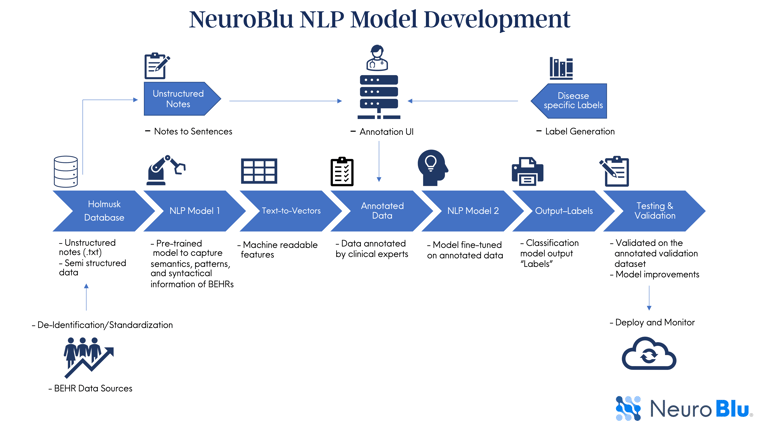
The model development process involves a combination of models, stacked one on the other, i.e., a pre-trained model further fine-tuned on the labeled data and lastly, the classifiers to predict the output. The outcome of this process is a single ensemble architecture, or a model specialized to process unstructured data and make predictions for a specific disease area, such as a depressive disorders model.
Clinical Data and Preprocessing
Unstructured clinical text, ranging from patient notes to psychological assessments, holds a wealth of information that often remains untapped due to its complexity. Our NLP models are trained on Holmusk’s rich patient-level EHR data at a large state-designated mental health network that comprises 200+ sites of care across both inpatient and outpatient settings.
We preprocess clinical text data to de-identify Protected Health Information (PHI), remove noise, correct errors, and standardize formatting. This step is crucial for building a high-quality pre-training dataset.
Annotations
One of the critical tasks in NLP is data annotation, which involves labeling and marking up linguistic data with specific information to train machine learning models, analyze text, or extract meaningful insights. The development of all NLP models begins with annotation, a process in which a specific set of clinical notes are annotated by Holmusk’s in-house team of trained clinicians. Because these clinicians have behavioral health expertise, they are able to label specific instances and provide important input that will be critical in training the models to recognize a wide variety of clinical contexts.
Training
Our development process consists of 2 stages:
Pre-training: We pre-train a given model using state-of-the-art models, such as BERT (Bidirectional Encoder Representations from Transformers), on non-annotated unstructured clinical text to transfer knowledge from a general language understanding context to a specific domain, providing a head start for domain-specific downstream tasks. BERT is built on the transformer architecture, which employs a self-attention mechanism. This mechanism allows the model to weigh the importance of different words in a sequence, capturing long-range dependencies and relationships more effectively. Our pre-trained model, pre-loaded with a broad understanding of language patterns from vast corpora (collections of written texts used to train the model), converts text into mathematical numbers. These numbers are called embeddings, a language that a computer understands and can process further to make predictions.
Fine-tuning: Fine-tuning is a machine learning technique that involves making small adjustments to a pre-trained model to improve its performance on a specific task when trained on annotated data. We fine-tune our model for extracting disease-specific clinical features such as anhedonia, suicidality, positive symptoms of schizophrenia, etc. on data annotated by clinical experts, making the model efficient in recognizing and extracting these features from EHR notes.
Holumusk’s NLP models use novel fine-tuning methods like "triplet-loss" to enhance learnings and boost text classification capabilities of the model on highly context-specific clinical language. A fine-tuned model is then combined with a suitable classifier like KNN or Random Forest to capture the context and make predictions on the given set of notes for the presence or absence of specific sets of clinical features across different mental disorders.
Our choice of model architecture and fine-tuning methods are based on extensive research and experimentation in developing domain-adapted language models in mental health.
Testing and Validation
Testing and validation of all NLP models are critical steps in the development lifecycle, essential for ensuring the reliability, accuracy, and generalizability of the models.
At Holmusk, models are tested by benchmarking the performance of our NLP models against existing domain adapted models like BioClinicalBERT and MentalBERT, with predefined metrics such as precision and recall, F1 score, and accuracy. Precision can be seen as a measure of quality, and recall as a measure of quantity. Higher precision means that an algorithm returns more relevant results than irrelevant ones, and high recall means that an algorithm returns most of the relevant results (whether or not irrelevant ones are also returned). The accuracy metric computes how many times a model made a correct prediction across the entire dataset, while F1 score is a weighted harmonic mean of precision and recall. In classification models, a large F1 score close to 1 indicates excellent precision and recall, while a low score close to 0 indicates poor model performance.
We validate our models against diverse datasets to ensure their robustness in handling real-world variability of clinical data.
Deployment
NLP disease-specific models, after thorough validation, are deployed through a well-designed engine, processing thousand of unstructured notes for generating inference. Healthcare data is sensitive, and ethical considerations are paramount. At Holmusk, NLP deployment engines are well-equipped with de-identification and anonymization techniques to remove or encrypt Protected Health Information (PHI), compliant with the Health Insurance Portability and Accountability Act (HIPAA). The product team conducts tests to ensure the model is functioning as expected within the software, and then deploys it for use within NeuroBlu.
Monitoring and Continuous Improvements
The evolving nature of language and healthcare practices demands continuous assessment of our models by incorporating feedback from domain experts and healthcare professionals. We iteratively improve upon the models to adapt to emerging linguistic patterns and clinical practices.
Our models are monitored at fixed intervals to keep checks on clinical relevance of their output, any deviations from expected performance, changing characteristics of new data, and potential breaches of sensitive data. These practices ensure that the model remains effective, ethical, and aligned with the evolving needs of users and stakeholders.
We ensure that model output is validated for potential data or performance drifts at each stage of development and even post integration. An output from the model on a randomly selected set of notes is sent back over to Holmusk’s clinical experts to identify areas for potential improvement and verify that the information extracted is accurate and clinically relevant.
Based on the regular inputs of our experts, models are continuously refined and generalized on new data to align with medical standards, terminology, and the subtleties of patient records.
With these models, we have demonstrated that granular symptomology data can be captured through the application of a novel, fit-for-purpose NLP model to unstructured real-world data. We will persistently refine and develop state-of-the-art NLP models, unveiling the latent potential within unstructured clinical notes. This is a significant step towards advancing the use of objective real-world evidence, which is particularly lacking for mental health disorders.
The journey to develop NLP models that extract clinical features is not merely a technological endeavor - it is a profound mission to reinvent behavioral health and transform lives through real-world evidence, AI-powered analytics, and digital solutions. The path to transforming mental health is dynamic and collective. At Holmusk, we are proud to be at the forefront, steering the course towards a future where the intersection of NLP and mental health is a catalyst for positive change.
Resources:
Deepali Kulkarni, Abhijit Ghosh, Amey Girdhari, Shaomin Liu, L. Alexander Vance, Melissa Unruh, Joydeep Sarkar, Enhancing pre-trained contextual embeddings with triplet loss as an effective fine-tuning method for extracting clinical features from electronic health record derived mental health clinical notes, Natural Language Processing Journal, Volume 6, 2024, 100045, ISSN 2949-7191, https://doi.org/10.1016/j.nlp.2023.100045
Yanli Liu, Y. W. (2012). New Machine Learning Algorithm: Random Forest. Lecture Notes in Computer Science, vol 7473. Springer, Berlin, Heidelberg, 2-11.
.png)
